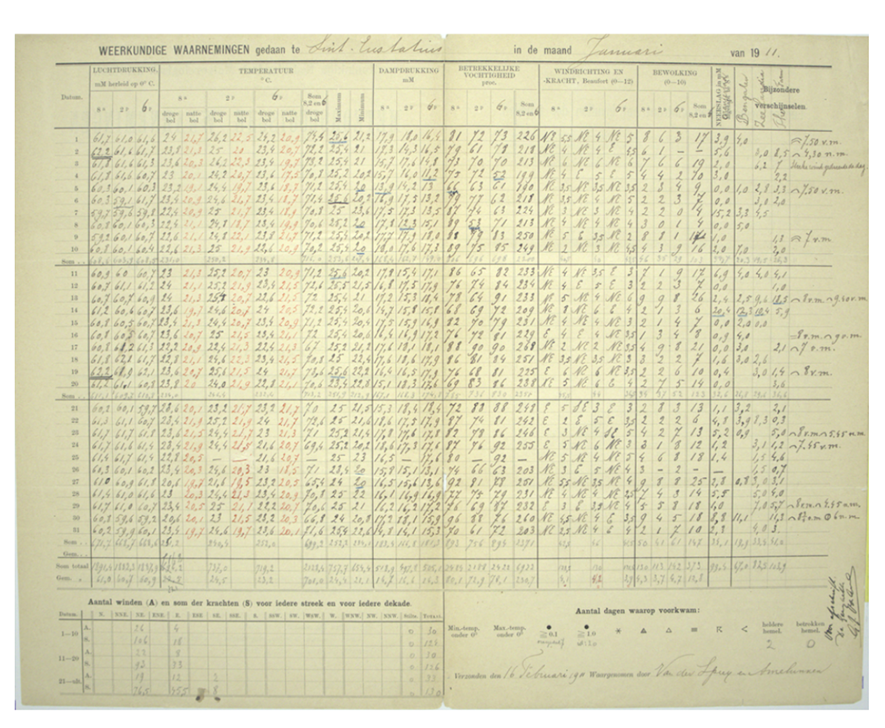
Knowledge about past climate and extreme weather events are an essential part of understanding future climate change and variability. Historically, knowledge about past weather events is under-represented in less-developed parts of the world, while digitized past climate information in developed nations is much more prevalent. Undigitized paper archives are often the only record of historical climate variability, and many are stored in vulnerable environments. Today, archives are digitized by experienced typists, or citizen science projects, which are both costly and time consuming. Development of specialised software like Meteosaver (Muheki et al., 2025) is a promising application of AI in the field but with limited generalisability to other data rescue applications (Peeters 2025). Recent advances in large language models suggest that vision-language models may also hold promise for automation of the climate data rescue task. This project could explore two potential avenues to exploit AI for data rescue:
1. Use of commercial large language models to generate training data: Peeters (2025) demonstrated the use of Gemini to generate a training dataset for subsequent fine- tuning of an OCR model. While the Gemini transcriptions were generally accurate, the usefulness of the method was limited by the separate cell detection step and matching the low-quality cell detection with the Gemini transcriptions. We propose the development of a new workflow that avoids matching errors by using Gemini to transcribe only the detected cells.
2. Direct use of open-source vision-language models: local hosting of model is attractive for many reasons, such as increasing customizability of the model. We propose exploring the accuracy of popular open-source VLMs, (e.g., dots.ocr, Donut, LayoutLMv3, NuMarkdown-8B-Thinking), and whether the accuracy can be increased by fine-tuning on KNMI’s specific tables. Advice on the number of training samples necessary to boost performance would be welcome by the meteorological data rescue community.
References
Muheki, D., Vercruysse, B., Chandrasekar, K.K.T., Verbruggen, C., Birkholz, J.M., Hufkens, K., Verbeeck, H., Boeckx, P., Lampe, S., Hawkins, E. and Thorne, P., 2025. MeteoSaver v1.0: a machine-learning based software for the transcription of historical weather data. EGUsphere, 2025, pp.1-52.
About KNMI
Koninklijk Nederlands Meteorologisch Instituut (KNMI) or The Royal Netherlands Meteorological Institute in English, is the Dutch national weather forecasting service, which has its headquarters in De Bilt, in the province of Utrecht, central Netherlands. The primary tasks of KNMI are weather forecasting, monitoring of climate changes and monitoring seismic activity. This project will be done with the Climate Services team in the department ‘R&D Observations and Data Technology’. KNMI will provide the student with meteorological data forms both already digitized for labelling or training data and new test sets.
Requirements: regular in-person visits to KNMI, De Bilt (at least one time a week).
Internship allowance according to Werken bij de Rijksoverheid.
Contact: Yuliya Shapovalova, Kirien Whan, .
Figure 1. Meteorological observations from St Eustatius from January 1911
%