This is an MSc thesis/internship project for a student with a strong quantitative background (math, physics, software engineering, or equivalent) and a good working knowledge of data processing with Python.
Most power failures in the medium voltage power grid occur in underground cable joints. These connections between cables are the weak spots of a cable system. Alliander uses online partial discharge (PD) monitoring to prevent power outages. Partial discharges are small sparks in the insulation of cables and joints that precede a full breakdown. By detecting such partial discharges early, discharging cable joints can be replaced before they fail and cause a power outage. Currently, around 15% of the MV grid is measured by 2300 sensors systems.
Because of the large quantity of data generated continuously, machine learning methods are used to process the data into useful grid warnings. These warnings can then be handled by a grid operator who decides whether to replace a joint or not. An important step in this process is the clustering of partial discharge data. The objective of this step is to cluster the datapoints that come from a common source, either PD or noise, together for further analysis.
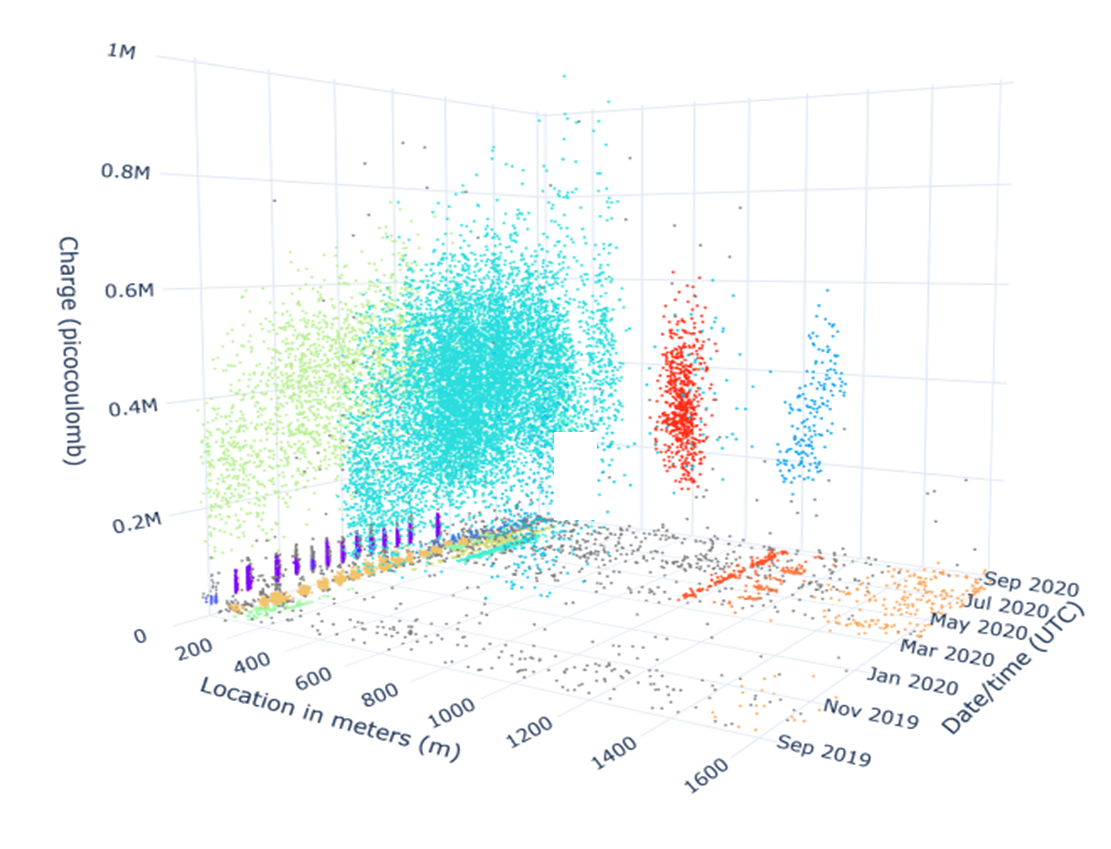
Currently we use HDBSCAN [1], a density-based clustering algorithm for this task. A feature of this model is that it can identify clusters of very different densities. Although the model produces good results for most circuits, there are issues with certain cable circuits. A more fundamental problem is that it is difficult to define a good clustering. Currently this is based on visual inspection. In this project we want to investigate the best possible clustering algorithm for our problem and data, and how to optimally calibrate it.
Supervisors at Alliander: Sander Rieken, Simon Bleuzé
Supervisors at Radboud: Yuliya Shapovalova